搜索引擎每天会接收大量的用户搜索请求,它会把这些用户输入的搜索关键词记录下来,然后再离线统计分析,得到最热门TopN搜索关键词。
现在有一包含10亿个搜索关键词的日志文件,如何能快速获取到热门榜Top 10搜索关键词? 可用堆解决,堆的几个应用:优先级队列、求Top K和求中位数。
优先级队列
首先应该是一个队列。队列最大的特性FIFO。 但优先级队列中,数据出队顺序是按优先级来,优先级最高的,最先出队。
方法很多,但堆实现最直接、高效。因为堆和优先级队列很相似。一个堆即可看作一个优先级队列。很多时候,它们只是概念上的区分。
- 往优先级队列中插入一个元素,就相当于往堆中插入一个元素
- 从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素
优先级队列应用场景非常多:赫夫曼编码、图的最短路径、最小生成树算法等,Java的PriorityQueue。
合并有序小文件
- 有100个小文件
- 每个文件100M
- 每个文件存储有序字符串
将这100个小文件合并成一个有序大文件,就用到优先级队列。 像归排的合并函数。从这100个文件中,各取第一个字符串,放入数组,然后比较大小,把最小的那个字符串放入合并后的大文件中,并从数组中删除。
假设,这最小字符串来自13.txt这个小文件,就再从该小文件取下一个字符串并放入数组,重新比较大小,并且选择最小的放入合并后的大文件,并且将它从数组中删除。依次类推,直到所有的文件中的数据都放入到大文件为止。
用数组存储从小文件中取出的字符串。每次从数组取最小字符串,都需循环遍历整个数组,不高效,如何更高效呢? 就要用到优先级队列,即堆:将从小文件中取出的字符串放入小顶堆,则堆顶元素就是优先级队列队首,即最小字符串。 将这个字符串放入大文件,并将其从堆中删除。 再从小文件中取出下一个字符串,放入到堆 循环该 过程,即可将100个小文件中的数据依次放入大文件。
删除堆顶数据、往堆插数据时间复杂度都是$O(logn)$,该案例$n=100$。 这不比原来数组存储高效多了?
2 高性能定时器
有一定时器,维护了很多定时任务,每个任务都设定了一个执行时间点。 定时器每过一个单位时间(如1s),就扫描一遍任务,看是否有任务到达设定执行时间。若到达,则执行。
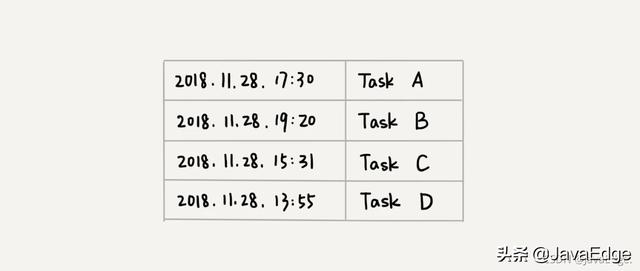

显然这样每过1s就扫描一遍任务列表很低效:
- 任务约定执行时间离当前时间可能还很久,这样很多次扫描其实都无意义
- 每次都要扫描整个任务列表,若任务列表很大,就很耗时
这时就该优先级队列上场了。按任务设定的执行时间,将这些任务存储在优先级队列,队首(即小顶堆的堆顶)存储最先执行的任务。
这样,定时器就无需每隔1s就扫描一遍任务列表了。
$队首任务执行时间点 – 当前时间点相减 = 时间间隔T$
T就是,从当前时间开始,需等待多久,才会有第一个任务要被执行。 定时器就能设定在T秒后,再来执行任务。 当前时间点 ~ $(T-1)s$ 时间段,定时器无需做任何事情。
当Ts时间过去后,定时器取优先级队列中队首任务执行 再计算新的队首任务执行时间点与当前时间点差值,将该值作为定时器执行下一个任务需等待时间。
如此设计,定时器既不用间隔1s就轮询一次,也无需遍历整个任务列表,性能大大提高。
利用堆求Top K
求Top K的问题抽象成两类:
静态数据集合
数据集合事先确定,不会再变。
可维护一个大小为K的小顶堆,顺序遍历数组,从数组中取数据与堆顶元素比较:
- >堆顶 删除堆顶,并将该元素插入堆
- <堆顶 do nothing,继续遍历数组
等数组中的数据都遍历完,堆中数据就是Top K。
遍历数组需要$O(n)$时间复杂度 一次堆化操作需$O(logK)$时间复杂度 所以最坏情况下,n个元素都入堆一次,所以时间复杂度就是$O(nlogK)$
动态数据集合
数据集合事先并不确定,有数据动态地加入到集合中,也就是求实时Top K。 一个数据集合中有两个操作:
- 添加数据
- 询问当前TopK数据
若每次询问Top K大数据,都基于当前数据重新计算,则时间复杂度$O(nlogK)$,n表示当前数据的大小。 其实可一直都维护一个K大小的小顶堆,当有数据被添加到集合,就拿它与堆顶元素对比:
- >堆顶 就把堆顶元素删除,并且将这个元素插入到堆中
- <堆顶 do nothing。无论何时需查询当前的前K大数据,都可以里立刻返回给他
利用堆求中位数
求动态数据集合中的中位数:
- 数据个数奇数 把数据从小到大排列,第$\frac{n}{2}+1$个数据就是中位数
- 数据个数是偶数 处于中间位置的数据有两个,第$\frac{n}{2}$个、第$\frac{n}{2}+1$个数据,可随意取一个作为中位数,比如取两个数中靠前的那个,即第$\frac{n}{2}$个数据
一组静态数据的中位数是固定的,可先排序,第$\frac{n}{2}$个数据就是中位数。 每次询问中位数,直接返回该固定值。所以,尽管排序的代价比较大,但是边际成本会很小。但是,如果我们面对的是动态数据集合,中位数在不停地变动,如果再用先排序的方法,每次询问中位数的时候,都要先进行排序,那效率就不高了。
借助堆,不用排序,即可高效地实现求中位数操作: 需维护两个堆:
- 大顶堆 存储前半部分数据
- 小顶堆 存储后半部分数据 && 小顶堆数据都 > 大顶堆数据
即若有n(偶数)个数据,从小到大排序,则:
- 前 $\frac{n}{2}$ 个数据存储在大顶堆
- 后$\frac{n}{2}$个数据存储在小顶堆
大顶堆中的堆顶元素就是我们要找的中位数。
n是奇数也类似:
- 大顶堆存储$\frac{n}{2}+1$个数据
- 小顶堆中就存储$\frac{n}{2}$个数据
数据动态变化,当新增一个数据时,如何调整两个堆,让大顶堆堆顶继续是中位数, 若:
- 新加入的数据 ≤ 大顶堆堆顶,则将该新数据插到大顶堆
- 新加入的数据大于等于小顶堆的堆顶元素,我们就将这个新数据插入到小顶堆。
这时可能出现,两个堆中的数据个数不符合前面约定的情况,若:
- n是偶数,两个堆中的数据个数都是 $\frac{n}{2}$
- n是奇数,大顶堆有 $\frac{n}{2}+1$ 个数据,小顶堆有 $\frac{n}{2}$ 个数据
即可从一个堆不停将堆顶数据移到另一个堆,以使得两个堆中的数据满足上面约定。
插入数据涉及堆化,所以时间复杂度$O(logn)$,但求中位数只需返回大顶堆堆顶,所以时间复杂度$O(1)$。
利用两个堆还可快速求其他百分位的数据,原理类似。 “如何快速求接口的99%响应时间?
中位数≥前50%数据,类比中位数,若将一组数据从小到大排列,这个99百分位数就是大于前面99%数据的那个数据。
假设有100个数据:1,2,3,……,100,则99百分位数就是99,因为≤99的数占总个数99%。
那99%响应时间是啥呢?
若有100个接口访问请求,每个接口请求的响应时间都不同,如55ms、100ms、23ms等,把这100个接口的响应时间按照从小到大排列,排在第99的那个数据就是99%响应时间,即99百分位响应时间。
即若有n个数据,将数据从小到大排列后,99百分位数大约就是第n99%个数据。 维护两个堆,一个大顶堆,一个小顶堆。假设当前总数据的个数是n,大顶堆中保存n99%个数据,小顶堆中保存n*1%个数据。大顶堆堆顶的数据就是我们要找的99%响应时间。
每插入一个数据时,要判断该数据跟大顶堆、小顶堆堆顶的大小关系,以决定插入哪个堆:
- 新插入数据 < 大顶堆的堆顶,插入大顶堆
- 新插入的数据 > 小顶堆的堆顶,插入小顶堆
但为保持大顶堆中的数据占99%,小顶堆中的数据占1%,每次新插入数据后,都要重新计算,这时大顶堆和小顶堆中的数据个数,是否还符合99:1:
- 不符合,则将一个堆中的数据移动到另一个堆,直到满足比例 移动的方法类似前面求中位数的方法
如此,每次插入数据,可能涉及几个数据的堆化操作,所以时间复杂度$O(logn)$。 每次求99%响应时间时,直接返回大顶堆中的堆顶即可,时间复杂度$O(1)$。
含10亿个搜索关键词的日志文件,快速获取Top 10
很多人肯定说使用MapReduce,但若将场景限定为单机,可使用内存为1GB,你咋办?
用户搜索的关键词很多是重复的,所以首先要统计每个搜索关键词出现的频率。 可通过散列表、平衡二叉查找树或其他一些支持快速查找、插入的数据结构,记录关键词及其出现次数。
假设散列表。 顺序扫描这10亿个搜索关键词。当扫描到某关键词,去散列表中查询:
- 存在,对应次数加一
- 不存在,插入散列表,并记录次数1
等遍历完这10亿个搜索关键词后,散列表就存储了不重复的搜索关键词及出现次数。
再根据堆求Top K方案,建立一个大小为10小顶堆,遍历散列表,依次取出每个搜索关键词及对应出现次数,然后与堆顶搜索关键词对比:
- 出现次数 > 堆顶搜索关键词的次数 删除堆顶关键词,将该出现次数更多的关键词入堆。
以此类推,当遍历完整个散列表中的搜索关键词之后,堆中的搜索关键词就是出现次数最多的Top 10搜索关键词了。
但其实有问题。10亿的关键词还是很多的。 假设10亿条搜索关键词中不重复的有1亿条,如果每个搜索关键词的平均长度是50个字节,那存储1亿个关键词起码需要5G内存,而散列表因为要避免频繁冲突,不会选择太大的装载因子,所以消耗的内存空间就更多了。 而机器只有1G可用内存,无法一次性将所有的搜索关键词加入内存。
何解?
因为相同数据经哈希算法后的哈希值相同,可将10亿条搜索关键词先通过哈希算法分片到10个文件:
- 创建10个空文件:00~09
- 遍历这10亿个关键词,并通过某哈希算法求哈希值
- 哈希值同10取模,结果就是该搜索关键词应被分到的文件编号
10亿关键词分片后,每个文件都只有1亿关键词,去掉重复的,可能就只剩1000万,每个关键词平均50个字节,总大小500M,1G内存足矣。
针对每个包含1亿条搜索关键词的文件:
- 利用散列表和堆,分别求Top 10
- 10个Top 10放一起,取这100个关键词中,出现次数Top 10关键词,即得10亿数据的Top 10热搜关键词
如若转载,请注明出处:https://www.sumedu.com/faq/255140.html
相关推荐
-
怎么去推广产品(如何去推广产品)
首先,需要做好产品定位和市场定位,#最基础的,然后是市场宣传,可以考虑以下方式: 1,淘宝天猫京东等电商推广 开通电商销售渠道,做好运营。 2,社区论坛推广 论坛和社区的发帖和回帖…
-
快手怎么建立自己的粉丝团群聊(快手怎么建立自己的粉丝团群微信)
圈层消费和精准营销的时期,有目标、有构造、有关键点。 “粉丝社群营销”是粉丝自发性产生的社团组织,伴随着互联网对日常生活的渗入,粉丝社群营销的服务平台迁移至互联网,产生了全新升级的…
-
苹果wapi是什么意思,干嘛用_(苹果的wapi是什么功能)
较适合想要进一步玩转iPhone的小伙伴,这里也一并分享给大家。 首先我们来重新认识下-设置-这个iPhone自带软件,我们可以看到五颜六色的各种图标,以及滑不到底的需求入口,苹果…
-
电话销售的好处和坏处(做电话销售头疼的危害)
小武刚毕业那会儿,互联网技术都还没有今日那么发达,信息传播也十分阻塞。 公司招不上人,应届毕业生找工作难,校园招聘和人力资源市场变成大学毕业生最重要的就业方式。 六月校园内参与完毕…
-
拼多多免单下单全额返是真的吗2022,拼多多免单3单是真的吗?
从昨天开始,我周边很多小伙伴收到了饿了么推送的免单短信。 登陆社交平台,很多网友也在晒饿了么订单金额被退回平台钱包的截图, 小到十几,大到上百。 这究竟是怎么回事?最重要的是,我为…
-
开咖啡店的商业计划书(开咖啡店需要什么执照)
开店计划 经营一家店、一个品牌,大多是从一个想法开始发展,但要想实现,就需要制定完整的计划,理清理想与现实之间的差距。 近年来国内的咖啡馆淘汰率极高,如何立足于如此激烈的市场中,建…
-
手机兼职短视频点赞员,点赞任务兼职?
近年来,各种新型电信网络诈骗层出不穷,其中刷单返利类诈骗一直占据首要位置。随着反诈宣传和打击工作的不断深入,过去常见的刷单诈骗逐渐与其他类型诈骗融合在一起,呈现出新的复合型诈骗特点…
-
tod项目是什么意思,地产tod项目是什么意思?
随着大湾区轨道交通线网日趋密集,TOD开发模式在佛山掀起了一股热潮。 南方日报记者 戴嘉信 摄 沿着佛山地铁2号线看禅城,南庄站地铁上盖,正谋划启动TOD开发,建设城市服务综合体;…
-
菜鸟驿站投诉电话人工服务电话,菜鸟驿站人工投诉电话号码?
取快递、拆快递 对于年轻人来说, 已经成为了生活日常。 哈尔滨的 十多天了也没送到。 5月18日,在公司里清点货品时,接到了一个电话。 快递公司经营者 孙明慧 有个客户给我打电话说…
-
居家线上教学什么意思(线上教学什么意思啊_)
疫情当下,为了停课不停学,各地纷纷采取线上教学模式。线上教学,一般采取的有三种方式:一是老师选择并推荐网络优秀教学资源,让学生观看;二是老师自身开网络直播,与学生“面对面”互动;三…