

作者丨房庆凯
1 前言
在这个信息全球化的时代,人们能够通过互联网轻松接触到来自世界各地的信息,了解异国他乡的风土人情。然而,语言不通常常成为我们网上冲浪过程中的最大阻碍。幸运的是,近年来迅猛发展的机器翻译技术已经能够在很大程度上帮助人们打破语言屏障,理解各种语言背后的信息。但随着互联网时代信息的呈现方式愈加丰富多样,例如声音、视频、直播等,简单的文本翻译已经不再能够满足人们的日常需求。

在这样的背景下,语音翻译技术应运而生。语音翻译,即将一种语言下的语音翻译为另外一种语言下的语音或文字,在当下有着广泛的应用场景:在线外语视频、跨国会议、出国旅游、国际贸易。与文本翻译相比,语音翻译通常面临更多的挑战,如何更准确地进行翻译成为了目前学术界和工业界十分关心的课题。
2 语音翻译的挑战
近年来,神经机器翻译技术取得的巨大进步,离不开大规模标注的平行语料数据。然而,语音翻译需要的“语音-转写-翻译”数据则相对较为稀少。例如,目前常用的语音翻译数据集大概只有几百小时。相比之下,文本翻译数据集通常具备百万甚至千万级的规模。因此,已有工作想方设法通过诸如预训练[1][2][3]、多任务学习[2][4][5]、知识蒸馏[5][6][7]等技术,利用大规模的文本翻译数据来帮助提高语音翻译模型的性能。
然而,想有效利用文本翻译数据并不容易,因为语音和文本之间存在着表示不一致的问题,本文称之为模态鸿沟 (Modality Gap) 问题。如下图所示,相同含义的语音表示和文本表示之间可能存在着较大的差异,此时模型难以从文本翻译数据中学习到对语音翻译有用的知识。
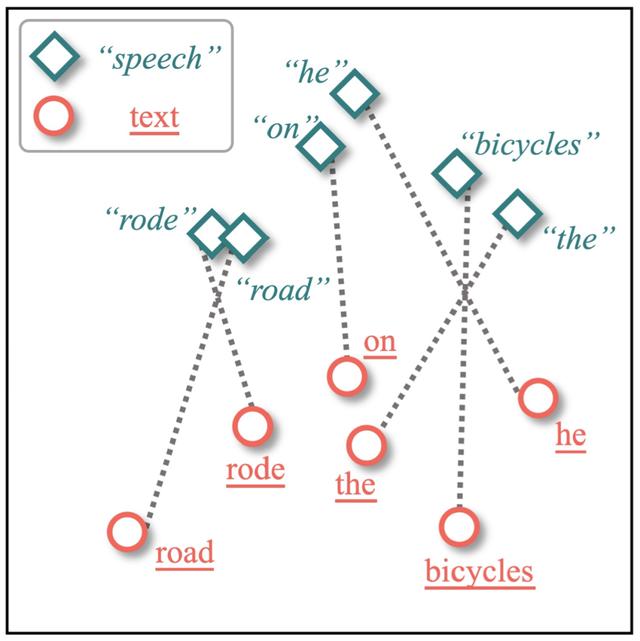
如何缓解语音与文本之间的模态鸿沟,有效利用文本翻译数据提高语音翻译的性能,是一个值得探究的问题。今天就为大家介绍一篇由中科院计算所、字节跳动 AI-Lab 与加州大学圣塔芭芭拉分校共同发表在ACL 2022上的长文 ——STEMM: Self-learning withSpeech-TExtManifoldMixup for Speech Translation[8]。
这篇文章针对语音翻译中的模态鸿沟问题,提出了一种简单有效的跨模态 Mixup 方法,通过 Mixup 产生同时包含语音表示和文本表示的序列,从而使模型在训练过程中建立模态间的联系。在此基础上,本文引入了一个自我学习框架,使语音翻译任务从 Mixup 中学习知识,进而提升语音翻译的性能。

3 STEMM 设计动机与方法
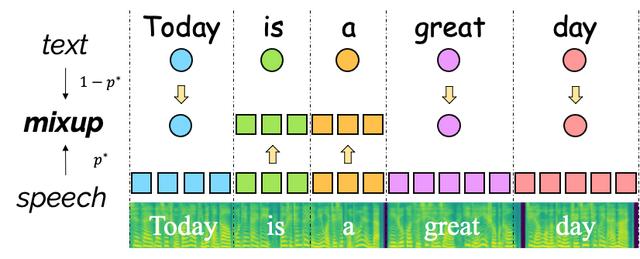
首先,想象一下,当我们听到一条语音“Nice to meet you”,或看到一条文字“Nice to meet you”时,我们都会将他们翻译为中文“很高兴见到你”,#因为不管这段话的载体是语音还是文字,在我们脑海中他们的意思都是一样的。进一步,假设这段话里某些单词的载体是语音,某些单词的载体是文字,如下图所示,我们还是能够理解不同载体(模态)背后相同的含义,并将他们翻译成同样的结果。

那么,机器是否能够做到这一点呢?答案是否定的,如上文所述,我们观察到不同模态数据的表示空间存在着较大的差异。在这种情况下,模型面对以上这种混合序列时会不知其所云。沿着该思路,我们考虑通过跨模态 Mixup 得到同时包含语音表示和文本表示的序列,并要求模型根据随机的混合序列预测翻译,通过这种方式使模型学习到模态间的映射关系。为了实现词级别的 Mixup,我们首先对语音和文本进行强制对齐(forced alignment),然后按一定概率 选取每个单词对应的文本表示或语音表示,将所有单词的表示拼接起来即为 Mixup 后的表示序列。
以 Mixup 序列作为输入来预测翻译,能够让模型更多的去关注序列所携带的语义信息,而非序列的模态信息,从而使模型学习到语音和文本模态间共享的语义空间。由于最终的目标是语音翻译,因此,我们通过多任务学习的方式,将语音序列和 Mixup 序列分别输入到模型中,并独立预测翻译结果。进一步,我们引入了一个自我学习框架,让两个翻译结果互相拉近,从而使语音翻译任务从 Mixup 序列的翻译结果中学习到对翻译有用的知识。最终的损失函数为模型根据语音序列、Mixup 序列预测的翻译结果与真实翻译之间的交叉熵损失,以及根据两个序列预测的翻译结果之间的 JS 散度。
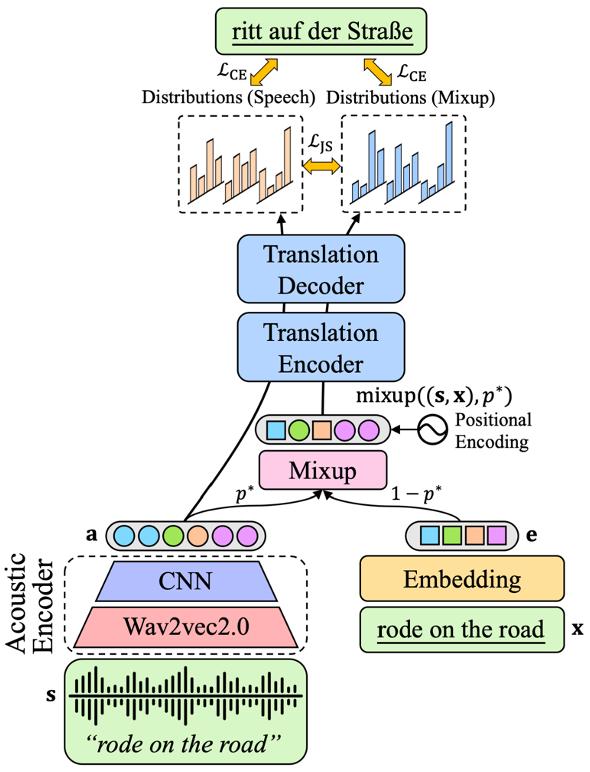
至此,本文的整体方法已介绍完毕。还有一个问题是:Mixup 的概率该如何设置?对于这一问题,本文提出了两种策略:
-
固定策略:在整个训练过程中,保持固定的 Mixup 概率。
-
自适应策略:根据语音翻译任务预测译文的不确定度 (uncertainty),决定每个样本的 Mixup 概率。
4 STEMM 实验结果及分析
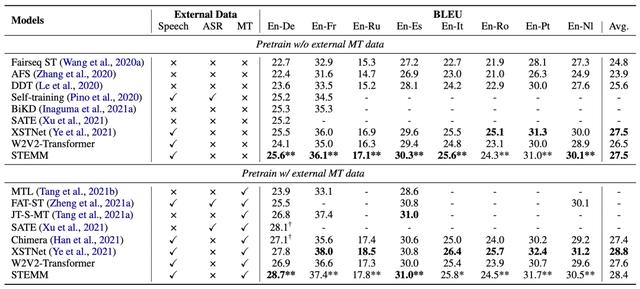
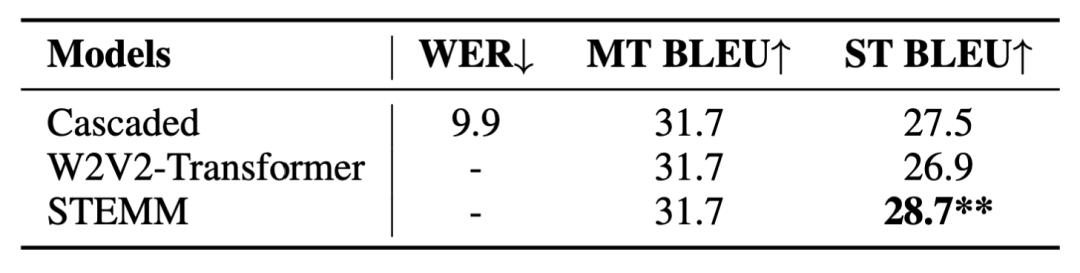
8 个语向取得翻译质量的显著提升
本文在 MuST-C 数据集的 8 个语向上进行了实验,如下表所示,与基线模型 W2V2-Transformer 相比,STEMM 在语音翻译质量上取得了显著的提升。同时,本文的方法也超越了众多已有工作。
显著超越级联模型
本文实现了一个强的级联语音翻译模型,其语音识别部分由 Wav2vec 2.0 和 6 层 Transformer decoder 组成,机器翻译部分与端到端模型的翻译部分相同。可以看到,端到端的 baseline 相比级联模型性能略差,而 STEMM 显著超越了级联模型的性能。
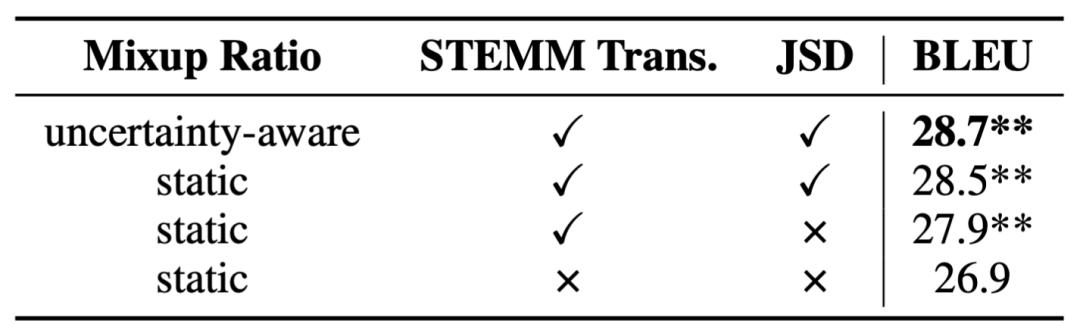
自适应策略表现更佳、两个训练目标均能带来提升
通过消融实验我们发现,Mixup 概率的自适应策略表现优于固定策略(对比第 1、2 行)。同时发现,除了语音翻译本身之外的两个训练目标均有显著作用。
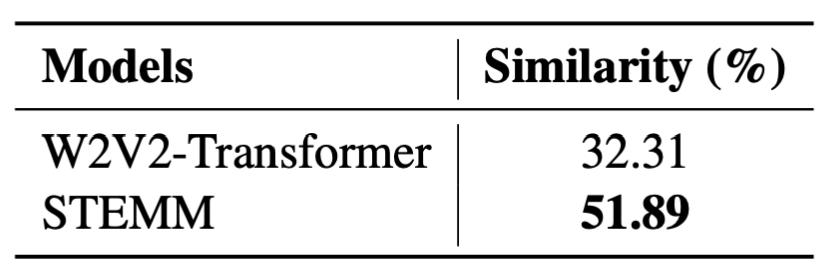
有效减小模态鸿沟
最后,回到本文开始提到的问题:语音和文本之间的模态鸿沟有没有得到缓解呢?我们统计了语音和文本两个模态下词级别表示的相似度,发现相比基线模型,我们的模型取得了显著的提升。从可视化结果来看,同一个单词在不同模态下的表示也有了一定的拉近。
5
总结
本文主要介绍了 ACL 2022 上的一篇工作,该工作提出了语音翻译的一种新方法 STEMM,其核心思想是通过跨模态的 Mixup 来减小语音和文本之间的模态鸿沟,并通过自我学习框架辅助语音翻译的训练。实验和分析表明该方法在语音翻译基准数据集 MuST-C 的所有语向上均取得了翻译性能的显著提升,同时有效减小了语音和文本之间的模态鸿沟。
传送门
最后,本文的代码和模型均已开源,代码基于 fairseq 实现,方便大家复现和使用,欢迎体验!
论文地址:https://aclanthology.org/2022.acl-long.486.pdf
代码地址:https://github.com/ictnlp/STEMM

参考文献
[1] Chengyi Wang, Yu Wu, Shujie Liu, Ming Zhou, and Zhenglu Yang. 2020. Curriculum Pre-training for End-to-End Speech Translation. In Proceedings of ACL 2020.
[2] Rong Ye, Mingxuan Wang, and Lei Li. 2021. End-to-end speech translation via cross-modal progressive training. In Proceedings of InterSpeech 2021.
[3] Chen Xu, Bojie Hu, Yanyang Li, Yuhao Zhang, Shen Huang, Qi Ju, Tong Xiao, and Jingbo Zhu. 2021. Stacked acoustic-and-textual encoding: Integrating the pre-trained models into speech translation encoders. In Proceedings of ACL 2021.
[4] Chi Han, Mingxuan Wang, Heng Ji, and Lei Li. 2021. Learning shared semantic space for speech-to-text translation. In Findings of ACL 2021.
[5] Yun Tang, Juan Pino, Xian Li, Changhan Wang, and Dmitriy Genzel. 2021. Improving speech translation by understanding and learning from the auxiliary text translation task. In Proceedings of ACL 2021.
[6] Yuchen Liu, Hao Xiong, Zhongjun He, Jiajun Zhang, Hua Wu, Haifeng Wang, and Chengqing Zong. 2019. End-to-end speech translation with knowledge distillation.
[7] Hirofumi Inaguma, Tatsuya Kawahara, and Shinji Watanabe. 2021. Source and target bidirectional knowledge distillation for end-to-end speech translation. In Proceedings of NAACL 2021.
[8] Qingkai Fang, Rong Ye, Lei Li, Yang Feng, Mingxuan Wang. 2022. STEMM: Self-learning with Speech-text Manifold Mixup for Speech Translation. In Proceedings of ACL 2022.

如若转载,请注明出处:https://www.sumedu.com/faq/79367.html
相关推荐
-
阿里巴巴国际站运营技巧分析论文(阿里巴巴国际站运营技巧分析怎么写)
阿里巴巴国际站运营思路 如今外贸行业不断发展,阿里巴巴国际站平台的竞争越来越大,产品同质化的现象也进入白热化阶段。一个能吸引全球买家的店铺需要全方位地展示外贸企业的情况和产品内容,…
-
中国制造网外贸平台怎么样收费(中国制造网外贸平台怎么样_)
其实觉得这个平台还是挺正点的。 首先,前面一篇文章讲过,这个平台还是有自己的思想的,至少不像当初苏宁易购那种墙头草两边倒般没有主心骨。 其次,后台非常的简单,因为这个平台有发品限制…
-
广告推广 精准引流,广告推广精准引流啥意思?
广告推广精准引流的重要性及实施方法 在如今的互联网时代,广告推广精准引流已成为企业营销中不可或缺的一环。广告推广精准引流主要指通过合适的广告渠道,将广告信息准确地传达给目标受众,从…
-
买新车平台(悦买车-最新新车上牌流程)
很多小伙伴买完新车准备上牌,为节省上牌时间,悦买车做了上牌流程梳理,供参考: 车主如何申请办理? 准备材料: 1.机动车所有人身份证明原件; 2.购车发票原件、车辆认证一致书等4S…
-
网络营销竞价推广(竞价推广有哪些)
会数据分析的人三下五除二就能解决问题; 不会分析数据的人面对杂乱的数据毫无头绪,更别说从数据中发现问题了。 数据分析的重要性,是所有竞价员都是高度一致认可的,但是竞价账户数据该怎么…
-
地推app拉新接任务平台(发布地推任务app)
了解地推优势,才能让你懂得做地推的决定是为了达成目标而执行的。并不是一时兴起,觉得地推很不错,就试试,然后下次就放弃了,这样不仅没有效果,还费时费力。如果你真的想做好地推活动,拉客…
-
微信群加僵尸粉哪里有(qq群拉僵尸粉一元200人网站)
图片来自网络 大连女孩小周花费1元钱,购买清理微信“僵尸粉”的程序。小周按照提示扫码操作,结果让她大吃一惊:1分钟内,父母、老师、同事等300个微信好友遭到删除。尴尬不已的小周只好…
-
企业税收标准是多少,企业税收标准是多少山西侯马新裕房地产有限公司
根据数据显示,2021年一季度全国共新注册市场主体583.6万家,同比增长58.3%,其中个体工商户378.1万家,其他各类企业共205.4万家。从月度数据来看,1月份注册量为…
-
金星直播秀在哪里看回放(金星直播秀在哪里看啊)
01 近日,金星现场直播现场,推销一款速食凉皮,价格颇为亲民,妆容精致的金姐还放下范儿当场试吃。 天气越来越热,南方已有进入初夏之感,清凉爽滑的凉皮正是应季之物。 正当直播间人数骤…
-
小程序拉新推广平台赚钱吗(拉新推广赚钱的小程序)
流量一直是很多人关注的问题,就拿小编公司给客户做的小程序来说,到第二年续费的时候,基本上只有个别几个客户还会续费,其他客户都已经放弃了,一问原因,都说是没有流量一分钱没有赚到,那本…