聚类是按照事物的某些属性,将数据对象分类,即与“物以类聚”相似。聚类分析将个体或对象分类,使得同一类对象之间的相似性比与其他类的对象的相似性更强。其目的在于使类内对象的同质性最大化,而类与类间对象的异质性最大化。在商业活动中,聚类分析用来对客户群体进行分类,并刻画各群体的特征。同时,聚类分析是细分市场的有效工具,可用于研究消费者行为和寻找潜在市场。
本章将介绍常见聚类方法的基本原理,让读者了解适合用聚类分析解决的问题,区分不同的聚类方法及其相关应用,掌握系统聚类和K-means聚类分析方法的SPSS Statistics 24.0具体操作步骤,并能够对分析结果进行解释,从而能够灵活运用聚类分析方法进行实际商务数据分析。
1 聚类分析概述
1.1 聚类分析简介
聚类分析是根据研究对象的特征,对研究对象进行分类。其基本思想是认为所研究的个案或变量之间存在着不同程度的相似性(亲疏关系)。
首先找出一些能够度量个案或变量之间相似程度的统计量,以此为划分类别的依据。然后,把一些彼此之间相似程度较大的聚合为一类,把另外一些彼此之间相似程度较大的聚合为另一类。关系密切的聚合到一个相对较小的分类单位,关系疏远的聚合到一个相对较大的分类单位,直到把所有的都聚合完毕,把不同类型一一划分出来,形成由小到大的分类系统。最后再把整个分类系统化成一张谱系图,用它把所有个案(或变量)间的亲疏关系表示出来。
值得注意的是,聚类分析可以当作一个独立的数据分析工具,也可以与其他方法如因子分析、判别分析、主成分分析等联合起来使用往往会取得较好的效果。
在商务经济领域中存在着大量的聚类问题,比如对我国所有省市自治区独立核算工业企业的经济效益进行分析,一般不是逐个省市自治区去分析,而较好的做法是选取能反映企业经济效益的代表性指标,如资金利税率、产值利税率、全员劳动生产率等。
根据这些指标对各个省市自治区进行分类,然后根据分类结果对企业经济效益进行综合评价,就易得出科学的分析。又比如商城希望对客户进行特征分析,其可从客户分类入手,根据客户的年龄、职业、收入、消费金额、消费频率、喜好等方面收集数据并进行聚类分析,从而得到客户分组。
此外,聚类技术还应用于医疗病患数据分析、图像分割、生物基因特征分类、地貌特征分类以及天文研究等方面。因此,聚类分析已越来越受到人们的重视。
在聚类分析中,根据分析对象的不同,可将聚类分析分为样品聚类和变量聚类。
(1)在实际中,应用较多的是样品聚类分析。样品聚类又称为Q型聚类,它是对个案进行聚类,使具有相似特征的个案聚集在一起,使差异性大的个案分离开来。也即对样本单位的观测量进行分类,以被观测对象的各种特征的各变量值为分类依据。
(2)变量聚类又称为R型聚类,它是对变量进行聚类,使具有相似性的变量聚集在一起,可在相似变量中选择少数具有代表性的变量参与其他分析,达到变量降维的目的。例如,在回归分析中由于自变量的共线性导致偏回归系数不能真正反映自变量对因变量的影响等。因此往往先要进行变量聚类,找出彼此独立且有代表性的自变量,而又不丢失大部分信息。
1.2 数据结构及数据标准化
1.数据结构
1)数据矩阵


2)相异度矩阵
相异度矩阵的实质是对象一对象结构,储存所有n个对象彼此之间的相似性。

因此相异度矩阵中对角线上的值全为0。
2.数据标准化
由于变量表示样本的各种性质,往往使用不同的度量单位,其观察值也可能相差比较大。这样,绝对值大的变量可能会湮没绝对值小的变量,使后者应有的作用得不到反映。为了确保各变量在聚类中的地位相同,可以对数据进行标准化变换,常用的有三种变换方法:
1)标准差标准化
记第j个属性的均值为:
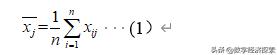
记第j个属性的标准差为:
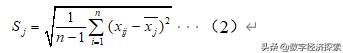
以下表示对第j个属性n个样本进行标准差标准化:

经变换后各变量的均值为0,标准差为1且与变量的量纲无关。
2)极差标准化
对第j个属性n个样本进行极差标准化:

经变换后各变量的均值为0,极差均为1。
1.3 相似性度量
聚类分析是根据事物的相似程度进行分类,因此,首先必须定义一个度量相似程度的指标。目前,主要用距离和相似系数作为相似程度的度量。
在选择相似性度量时,需要考虑的问题包括属性值的性质(离散型、连续型、二值型)、测量值的尺度(定类尺度、定序尺度、定距尺度、定比尺度),以及与研究问题相关的知识,通常会掺入相当大的主观性。在对样品进行聚类时,其相似性通常用距离度量来表示;在对变量进行聚类时,通常用相关系数或其他类似的相似性度量。
1.距离
1)满足条件

2)常见距离
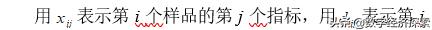
个样品与第j个样品之间的距离。其中当各指标的测量值相差悬殊时,先对数据标准化,然后,用标准化后的数据计算距离。最常见的距离有以下几种:
- 绝对值距离
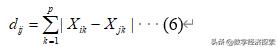
- 欧式距离
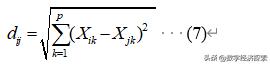
- 明考斯基距离

- 马氏距离
该距离对指标的相关性作了考虑且不受指标测量单位的影响。
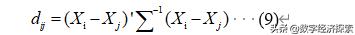
- 兰氏距离
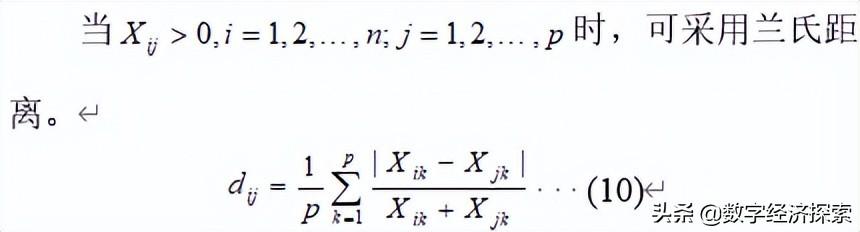
2.相似系数

越密切。换而言之,性质越接近的指标,它们的相似系数越接近于1。彼此无关的指标它们的相似系数越接近于0。完全相反的指标相似系数为-1,把比较相似的指标归为一类,相似程度小的指标属于不同的类,常用的相似系数(按指标)有
- 夹角余旋
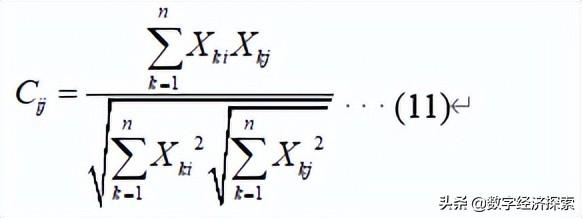
- 相关系数
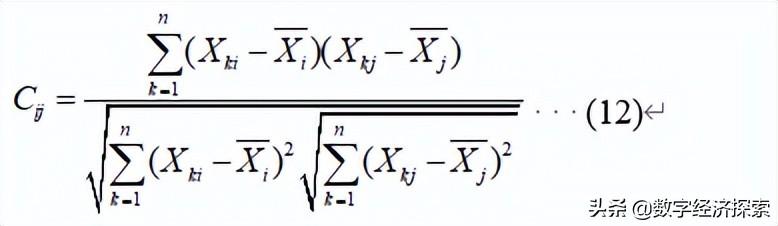
参考文献:
樊重俊等. 基于SPSS的商务数据分析方法(M). 上海:立信会计出版社. 2018.
何晓群. 多元统计分析(第四版)[M]. 北京: 中国人民大学出版社, 2015.





(数据分析知识系列由樊重俊教授团队撰写,转发本文请标明作者与出处。欢迎关注,带你一起长知识!)

如若转载,请注明出处:https://www.sumedu.com/faq/167121.html
相关推荐
-
赚零花钱的正规软件,赚零花钱软件微信提现?
凡事没有想清楚这8个问题点的人,很难赚到钱。 同样,就目前来看,凡是取得了一点成就的人都有这么一套方法论,而这套方法论文,我总结之后发现就是这8个问题。 每周读书会 俞军在他的产品…
-
抖音掉粉是什么原因引起的,抖音掉粉正常吗?
以前我不开直播的原因是粉丝量少,仅仅做媒体半年或一年,各路粉丝还没有聚集到成熟状态。 那么,现在我为什么开直播呢?哪是先预热预热而已,一则先熟悉直播程序,二呢,稳定一些老粉丝,有人…
-
gta5快速赚钱的方法线上,gta5快速赚钱的方法线上玩?
tx的最新FPS手游【暗区突围】今天上线了,这款主打硬核射击与死亡掉落的游戏怎么看都像是逃离塔科夫的简化版本 硬核与手游的结合总感觉很突兀 虽然暗区突围自身保留了许多手游FPS罕见…
-
向客户推销产品的话术(如何推销自己的产品话术)
有人说最高明的推销员是向乞丐推销防盗门、向和尚推销生发精、向秃子推销梳子、向瞎子推销灯炮的人。持这种观点的人认为,所谓推销,就是卖东西,即推销的中心问题,就是卖出商品,赚取利润。 …
-
小红书兼职平台一单一结是真的吗(小红书放单平台兼职)
抖音点赞返利 刷单赚取佣金 “每天只需一小时” “一单一结当天结算” 网上的各种兼职刷单 真的这么容易赚钱吗? 【全民学反诈:刷单诈骗】开学季,在校学生要注意,任何形式的刷单都是诈…
-
发型师朋友圈文案大全图片搞笑(发型师朋友圈文案大全图片女)
适合美容护肤行业的10条金句文案,这样发朋友圈,顾客追着你更! 1、能够抵挡岁月的容颜 往往都是童话故事 只有舍得投资自己 才能获得长久的美丽 也是对自己最好的人生态度 2、生命里…
-
对客户服务意识及态度的语句描述(客户服务意识怎么写)
服务态度和意识 网络无情人有情,在网络时代这么疯狂的形式下,您的真诚,您的努力,比您的言语更重要。 21世纪是比拼服务的时代,成功的销售目的不是为了完成一次交易而接近客户,而是长期…
-
日语零基础(学日语零基础)
很多日本文化爱好者都想通过学习人就要来更进一步对日本文化的了解,并因此开启了日语自学的征程。 小白请教,自学日语从哪里开始学 对日语有所了解的人都知道,不论是自学还是报班学习,都是…
-
有没有什么好的兼职可以做的(现在还有什么兼职比较好做)
文 | 有余姐 全文共1994字,阅读时长约4分钟 朋友孩子才过完一岁生日不久,就找我聊有什么兼职门路可以分享。 她说,生了娃之后,自己突然就像换了一个人,觉得之前的好多想法都很幼…
-
1688运营自学全套教程要多少钱(1688运营自学全套教程视频)
1688运营新玩法,千牛消息可以通过微信回复啦!下面多米咨询小编带你一步步进行设置。 1、绑定消息提醒渠道 接收提醒消息的前提,您需要先绑定一个接收消息的方式,我们当前为您提供4种…