

山丁
热衷于发现 善于思索
在解决问题的 过程中
发现了 有意思的产品
在疲惫不堪的 世俗中
妄想做英雄的 普通人
#山丁的第1篇原创
预计阅读时间6分钟
一
21世纪
还有必要学习爬虫吗?
我们是否真的需要?
答案是必然的,网络爬虫是一种按照一定规则自动抓取网页信息的脚本,在大数据时代早已融入生活的今天,如果你有对数据采集分析的需求,就一定会需要!
但往往学习的过程总是困难的,使得我们妥妥的“入门到放弃”
不如我们…
不如我们换一种方法?
如果只是工作或学习中需要采集互联网数据进行应用,可以先试试市面上的通用采集器,降低获取数据而投入的时间成本,从而能专注于自身。而后当我们的需求与日俱增,再去学习以“代码”的形式实现爬虫也不迟。
人的精力是有限的
与其泛泛而为,不如重点突破
先做你应该做的,再做你想做的
二
采集软件推荐
市面上的数据采集工具众多
目前活跃的有:
01 .集搜客(GooSeeker)
个人评价:学习成本相对较高,无自动采集,需要手动选择标签定义规则
推荐指数:
02 .八爪鱼采集器
个人评价:学习成本较低,有自动采集,没有针对反爬,IP,策略等(增量)功能的配置
推荐指数:
03 .后羿采集器
个人评价:学习成本极低,强大的自动采集,对小白极其友好
推荐指数:
下面我们就来聊聊
这款推荐指数五颗星的
软件是如何让我欲罢不能的
三
产品特点
1 .免费
数据采集到导出,一整套免费的流程
部分功能收费,例如高级数据去重,定时采集等..如果想白嫖使用,甚至不需要注册…
2 .适配多平台
分别适配Windows/Mac/Linux
3 .功能强大
两种模式 智能模式 与 流程图模式
3.1 智能模式
操作极其简单 输入网址 智能识别出网页中的内容
无需配置任何采集规则就能够完成数据的采集。
3.2 流程图模式
为了满足用户丰富的个性化数据采集需求而研发的操作模式。
以可视化的网页点选操作,只需要打开被采集的网站,用鼠标点击几下配置就能自动生成复杂的数据采集规则。
四
基础功能
1 .数据采集 – 文字
注:如图片模糊,所有高清图片会放在
文章底部>文件资料内
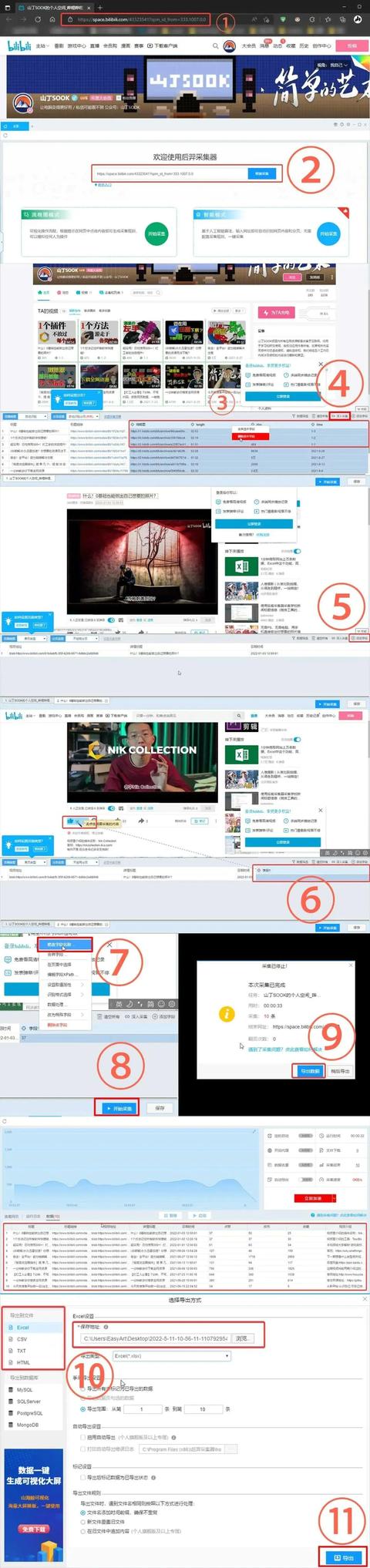
这里以采集B站Up主“山丁SOOK”
每期视频名称、视频介绍、发布时间、点赞、投币、收藏数目为案例
①复制Up主个人主页网页地址
??
②后裔采集器 输入网址 智能采集
??
可以看到已经把标题,链接,缩略图等数据自动分析出来了
③删除多余的数据
只剩下 标题 标题链接
??
那么 点赞 投币 收藏数目怎么获取呢?
??
④点击底部区域的右上角深入采集!
??
进入深度采集页面之后
需要我们手动添加数据
??
⑤单击右上角的添加字段 再将鼠标移至网页内
就会出现一个类似于“笔“的图标
并且与下方的新增字段有一条线链接
??
⑥把鼠标移动至 视频的点赞处 点击
??
就会发现下面新增了一列数据 就是我们的点赞数
??
⑦再右键点击“字段1” 重命名
输入点赞数
??
这样点赞数的采集就完成了
??
视频介绍,投币,收藏数分别添加完成后
??
⑧点击右下角的“开始采集”
??
就可以看到所有我们想要的数据已经乖乖的躺在里面了
??
⑨爬取完毕后 选择立即导出
??
⑩设定导出地址与类型
??
?点击导出
2 .数据采集 – 图片
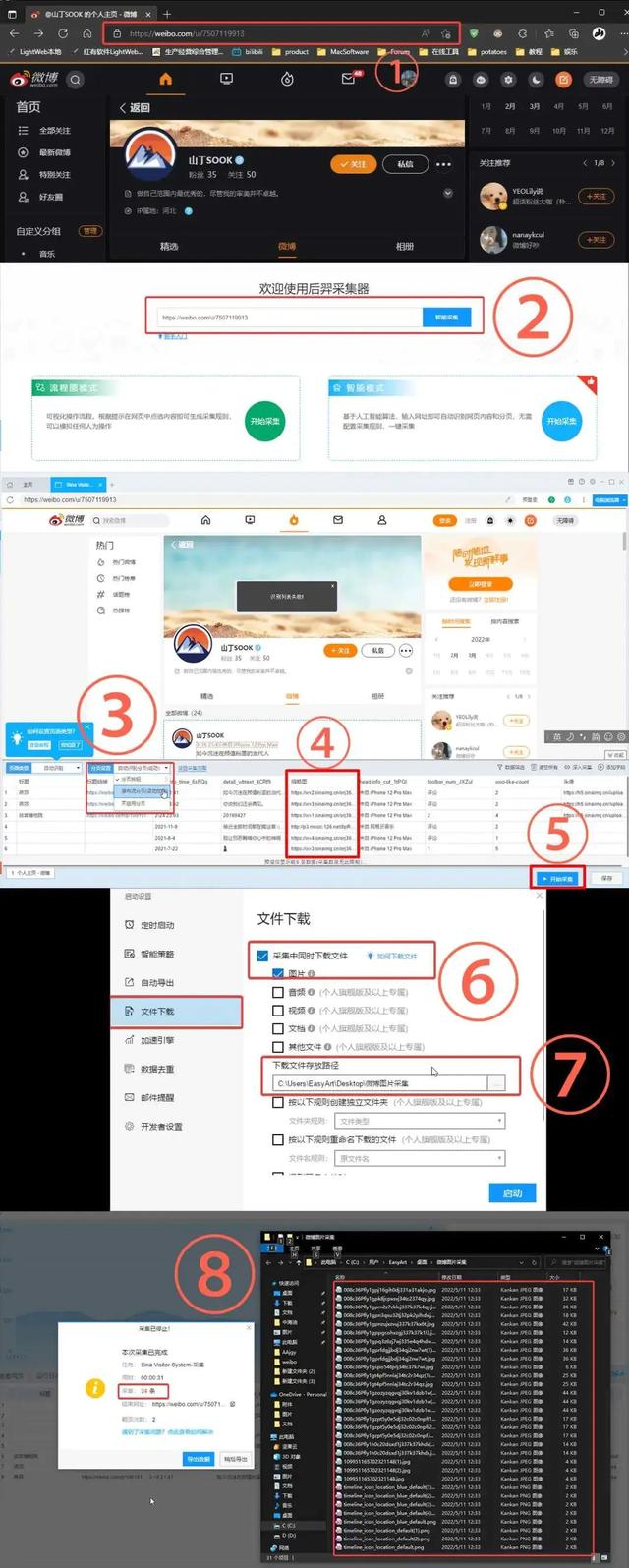
这里以采集微博“山丁SOOK”中发布的时间、正文、图片为案例
①复制微博主页网页地址
??
②打开采集器 输入网页地址 智能采集
??
弹出“识别列表失败”
“识别列表失败”是因为微博与其他网页的翻页形式不同
正常网页是底部有 1,2,3,4页 而微博则是瀑布流
③在分页设置中选择 瀑布流分页(滚动加载)
??
④可以看到采集器已经把图片的链接识别出来了
??
⑤点击开始采集
??
⑥选择左侧选项卡中的 文件下载
选中 采集中同时下载文件 图片
??
⑦设定图片下载的地址
??
⑧采集完成后就可以在文件夹中看到了
五
进阶使用
1 .流程图模式
流程图模式的本质是图形化编程。我们可以利用后裔采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
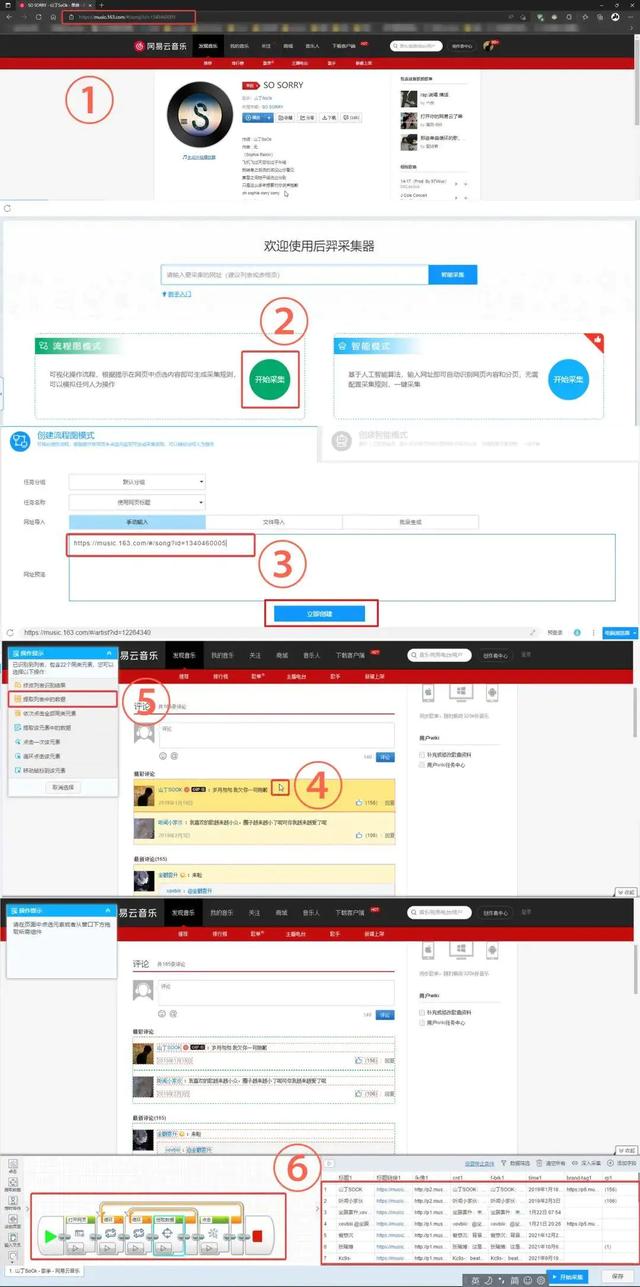
比如说下图这个流程图,就是模拟真人抓取网易云歌曲评论的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。
这里以流程图模式采集网易云“山丁SOOK”中单曲评论为例
①复制网易云网页地址
??
②后裔采集器中选择流程图模式 开始采集
??
③输入网址 立即创建
??
④进入到页面之后 将鼠标挪至评论区块 点击
??
⑤在左侧出现的操作提示中选择
“提取列表中的数据”
??
⑥可以看到下面已经为我们自动生成了循环判断语句
??
右侧抓取数据概览
??
下一步就是测试语句通顺,然后爬取,不再赘述
2 .数据清洗
数据清洗则是在开始采集任务之前的 数据去重选项卡内设定的去重条件,
有所有字段重复(免费),单独字段重复(收费)和当碰到重复数据所进行的操作,是跳过还是停止任务.

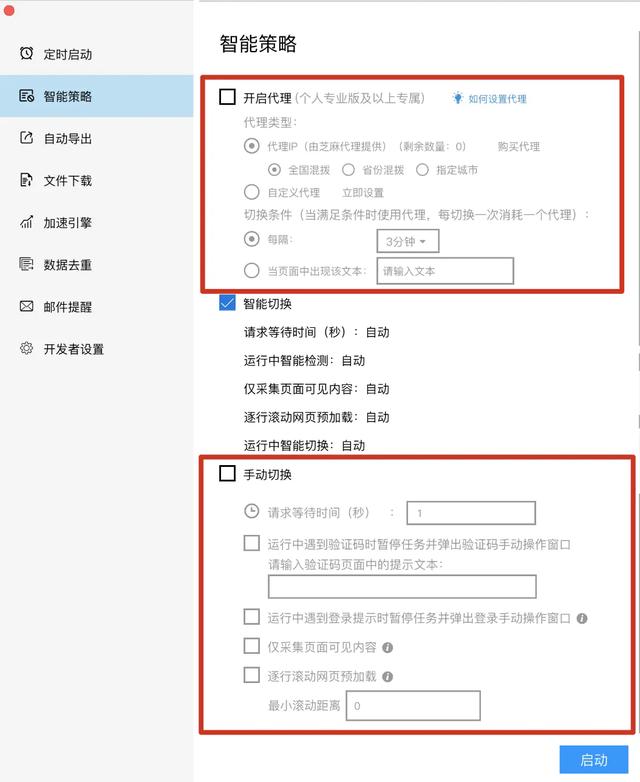
3 .IP代理切换
IP代理切换则是在开始采集任务之前的智能策略选项卡内设定.
免费版是自带了智能切换,但如果不能满足我们,我们也可以对代理进行单独的设定.
六
总结
经过我本人的平均一个月使用一次的经历,足以证明后羿采集器是非常贴合我的需求的,免费且功能强大,可以解决绝大部分编程小白的数据抓取需求
其他的高级功能还有很多
这里没有介绍到
但如果没有编程基础,把这些逻辑搞清楚,
也是对以后编程的学习有很大帮助的!
图片失效,在公众号:山丁SOOK
如若转载,请注明出处:https://www.sumedu.com/faq/87993.html
相关推荐
-
淘宝达人严选是正品吗知乎(淘宝达人严选都是正品吗)
夏天可以说是吃桃子的好季节,如今已经立秋了,桃子也越来越少了!想吃桃子吃不到的时候可以来做一做这款天仙蟠桃饼,用料简单也容易做!无意间翻淘宝看到很多淘宝达人都推荐这款天仙蟠桃饼,所…
-
京东新人一元购退出找不到了(京东新人一元购可以买几件)
小时候家里条件不是很好,在父母的教育下我很少乱花钱。现在长大了工资可以自由支配,但还是改不了这个习惯。日常买的东西,家里需要买的大件,都是比较完价格再买,坚决不花冤枉钱。例如洗衣液…
-
看小说赚钱软件排行榜第一名,看小说赚钱软件排行榜第一名ios?
当然靠谱! 我就是一名网络作者,虽然我总和大家说自己是一个扑街,但我也确实是挣了一点点钱的。 本人最开始接触网络小说是在上高中的时候,没错,我上过高中,只不过成绩不太好,连个本科都…
-
投资一两万的创业项目(两千元创业项目)
分享一个我内部团队最近测试的抖音小店项目 0基础小白摸索一个月,日均营业额2万左右,无货源项目,起店快,不推广,每月收益5000-10000+ 抖音小店资料移步小编xxck8863…
-
用电子身份证能坐火车吗(粤康码电子身份证能坐火车吗)
临时身份证,乘坐火车,稍显麻烦随着中国铁路的快速升级,乘坐火车外出旅游,已经成了非常方便的事情,凭借二代身份证,购买电子客票,就可以通过自动验票,乘坐火车外出旅游,不仅节省了排队取…
-
工业机器人培训骗局揭秘(工业机器人培训哪里最好)
自动化(工业机器人)人才培训课程介绍 序号 课程编号 课程名称 课时H 培训内容 学前技能要求 开课目的 1 MRC0301 工业机器人基础操作(kuka) 16 安全操作规范 高…
-
微信建群一定要面对面吗,微信建群一天有限制吗?
极目新闻记者 黄忠 摄影记者 刘中灿 阳光,草坪,森林书咖;月老,红娘,姻缘幕墙。 在26日的极目相亲大会现场,一切准备妥当,只为帮助单身男女青年,遇见最适合的TA! 边玩边相亲,…
-
淘宝网店铺怎么装修的步骤(淘宝店铺装修怎么弄)
很多商友在店铺首页装修上,都会遇到以下几个问题: ①如何排版才能最大化地延长客户在店浏览时间? ②店铺怎样装修才能脱颖而出? ③我不会ps、不会设计要如何做店铺装修? ……
-
百度律临代理商(百度律临收费吗)
什么是律临? 律临是百度赋能法律行业的律师推广平台。平台客观展示入驻律师的真实情况,与此同时百度给予律临平台极大的流量支持。用户通过搜索法律咨询相关关键词,在百度搜索结果页、百度智…
-
拼多多放心推效果怎么样会不会大量退货(拼多多放心推效果怎么样贴吧)
物流资讯 最新政策 国家邮政局发出通知要求开展邮政快递业安全生产大检查。 国家邮政局:清明假期全国邮政快递业揽投快递包裹13.5亿件。 一季度国家铁路发送货物9.48亿吨,同比增长…